阿里雲發佈端到端多模態AI模型Qwen2.5-Omni-7B
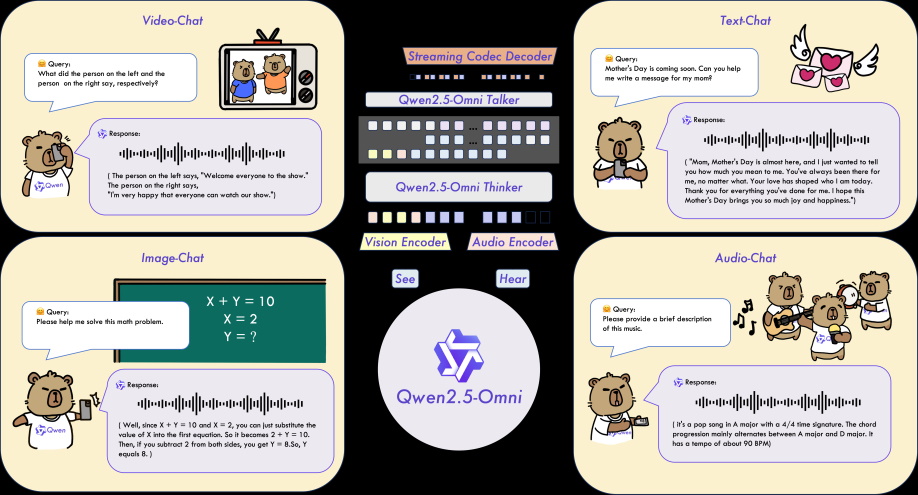
阿里雲發佈通義家族首個端到端全模態大模型Qwen2.5-Omni-7B。該模型專為全模態感知設計,可處理文本、圖像、音頻、視頻等多模態輸入,並實時生成文本與自然語言應答,為在手機、筆記本電腦等終端設備部署多模態AI設立新標準。
創新架構打造高性能表現
儘管僅採用了輕量級的7B參數,Qwen2.5-Omni-7B仍展現出卓越的性能與強大的多模態能力,成為開發高效能、高性價比、且具使用價值的AI智能體的理想基座模型,在智能語音應用領域尤其具有前景。例如,透過即時語音導航協助視障者安全辨識周邊環境,分析視頻中的食材按步驟提供烹飪指導,及打造真正理解客戶需求的智能客服對話體驗。
該模型現已在Hugging Face 與GitHub上開源,並可透過Qwen Chat及阿里雲開源社區ModelScope獲取。目前,阿里雲已開源超過200個生成式AI模型。
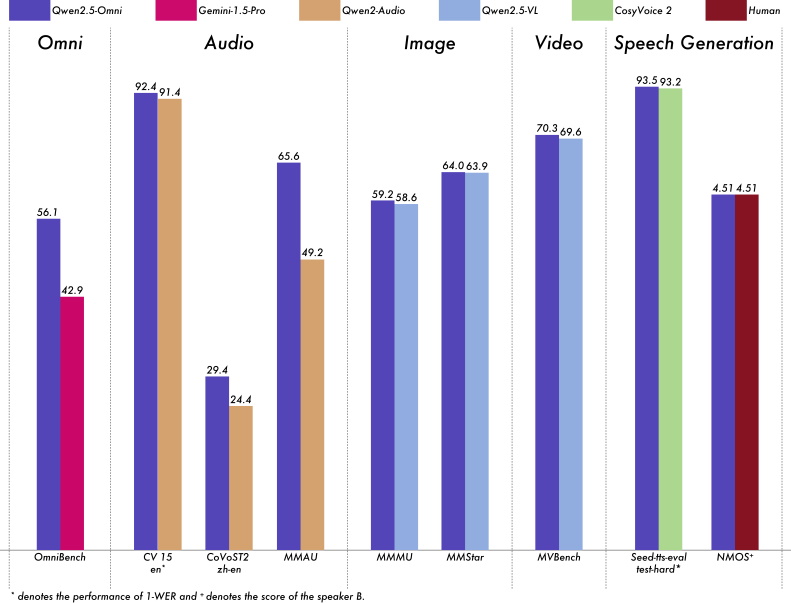
在各模態任務中,Qwen2.5-Omni-7B均展現出可媲美同參數規模的單模態專用模型的性能。該模型在實時語音交互、自然語言生成及端到端語言指令跟蹤方面表现出色。
其卓越效能源自三大創新架構:Thinker-Talker 架構透過分離文本生成(由Thinker處理)與語言合成(由Talker執行),降低多模態間的相互干擾,確保高品質輸出;TMRoPE (Time-aligned Multimodal RoPE) 位置編碼技術,通過時間軸對齊實現視頻與音頻輸入的精準同步,實現內容生成的高度連貫性;以及通過Block-wise Streaming Processing區塊串流處理技術實現低延遲音頻響應,打造無縫語音交互體驗。
輕量級參數的優異性能表現
Qwen2.5-Omni-7B基於海量多模態數據進行預訓練,涵蓋圖文、影片文、影音、音文及純文本數據,確保其在各項任務中皆能展現強健性能。
憑藉創新架構與高品質預訓練數據集,該模型在語音指令跟隨任務中表現卓越,性能直逼純文字輸入水準。在需要整合多模態的任務上(如OmniBench基準測試所評估的視覺、聽覺及文本輸入的識別、解讀與推理能力),Qwen2.5-Omni更達到業界頂尖水平。
通過情境學習(in-context learning,ICL),Qwen2.5-Omni-7B在語音理解與生成方面展现出卓越性能。經強化學習(reinforcement learning,RL)優化後,模型生成穩定性顯著提升,注意力偏移、發音錯誤與不當停頓現象大幅減少。
阿里雲於去年9月推出Qwen2.5系列,並於今年1月發布Qwen2.5-Max,該模型在Chatbot Arena排行榜上位列第七,性能可媲美頂級專有大語言模型並展現出卓越能力。阿里雲還開源了強化視覺理解能力的Qwen2.5-VL及專為處理長上下文輸入的Qwen2.5-1M。